
The first time you see your Obsidian graph after 30 days with claude-obsidian, you stop what you are doing. Hundreds of nodes, color-coded by domain, linked in patterns you never planned. Research papers ingested in January connected to project notes from March. Concepts you thought were unrelated had three paths between them in the graph. You did not write any of it. Claude did.
Every session started exactly where the last one left off. No recap, no context-rebuilding. The wiki knew what you knew.
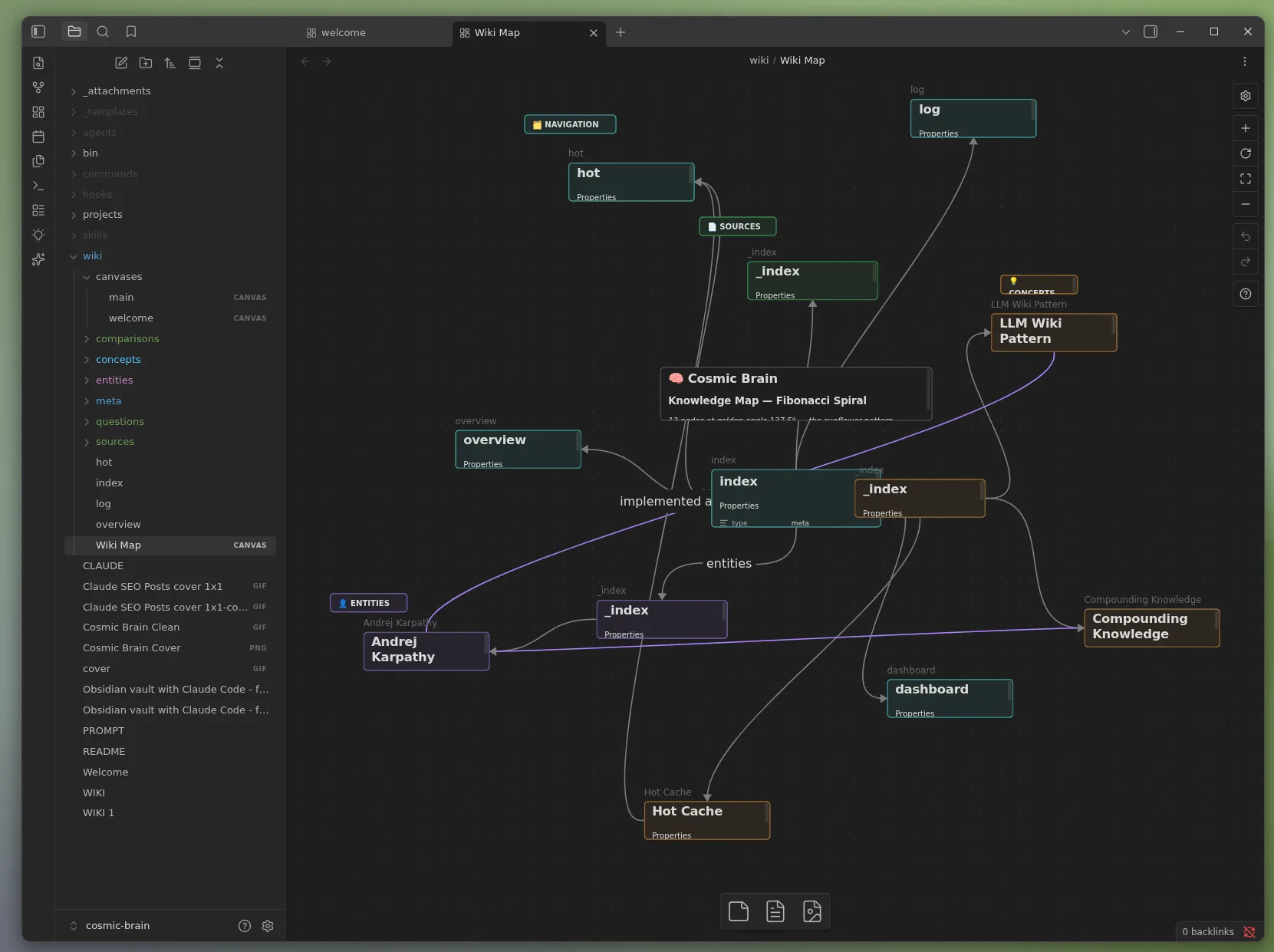
This is what Andrej Karpathy described in April 2026 when he shared his LLM Wiki pattern. Not a better RAG pipeline. Not a smarter search tool. A knowledge system that compounds. The longer you use it, the more valuable it becomes.
Here is how to build it in under two minutes with claude-obsidian, a free Claude Code plugin built directly on the Karpathy pattern.

What Is Karpathy's LLM Wiki Pattern?
Most people interact with LLMs through RAG. You upload documents, the system chunks them, converts to embeddings, stores in a vector database. When you query, it retrieves similar chunks and injects them as context. RAG works, but it does not accumulate. Every query is a fresh retrieval from static source material. The LLM rediscovers knowledge from scratch each time.
In April 2026, Karpathy shared a different approach: use an LLM to pre-compile sources into a structured markdown wiki, then operate on that wiki. Knowledge accumulates. Sessions build on each other.
The key insight: LLMs reason well over long structured text. They do not need embeddings to understand a well-organized markdown document.
Obsidian is the natural home for this pattern. Local markdown files, bidirectional links, graph view, no vendor lock-in. Your vault is just a folder of text files that Claude can read, write, and maintain.
Enter claude-obsidian
claude-obsidian is a Claude Code plugin implementing the Karpathy LLM Wiki pattern as ready-to-use skills. Nine skills working together:
| Skill | What it does |
|---|---|
/wiki | Setup check, scaffold vault, or resume where you left off |
ingest [file] | Reads a source, creates 8-15 interlinked wiki pages, updates index |
ingest all | Batch processes multiple sources with automatic cross-referencing |
/autoresearch [topic] | Autonomous loop: searches, fetches, synthesizes, files into wiki |
/canvas | Visual canvas control: images, notes, PDFs, pinned wiki pages |
/save | Files the current conversation as a dated wiki note |
lint | Health check: orphans, dead links, stale claims, missing references |
what do you know about X? | Q&A grounded in wiki content, not training data |
The hot cache is the most underrated feature. At the end of every session, Claude updates wiki/hot.md with a compact context summary. The next session reads that file first. You never rebuild context. The wiki already knows.

Quick Start, 3 Ways to Install
Option 1: Plugin Install (Recommended, 2 minutes)
claude plugin install github:AgriciDaniel/claude-obsidian
Open any project in Claude Code and type /wiki. Claude walks through vault setup, asks one question (What is this vault for?), then scaffolds the complete wiki structure.
Option 2: Clone as a Full Vault
git clone https://github.com/AgriciDaniel/claude-obsidian cd claude-obsidian bash bin/setup-vault.sh
Open in Obsidian: Manage Vaults, Open folder as vault. The graph launches pre-configured with color-coded node types.
Option 3: Add to an Existing Vault
Copy WIKI.md from the repo into your vault root. Paste into Claude: "Read WIKI.md in this project. Check if Obsidian is installed. Check if Local REST API plugin runs on port 27124. Configure MCP server. Ask me one question: What is this vault for? Then scaffold the full wiki structure."
Claude builds the wiki around your existing notes without overwriting anything.
Your First Ingest, Watch the Wiki Build Itself
ingest research-paper.pdf
Claude reads the source, extracts entities, creates 8 to 15 interlinked pages. Each page is a wiki entry: concept definition, entity profile, or relationship map. Every page cross-references related entries.
ingest all of these
Claude processes sequentially, cross-referencing across sources. A concept from a 2023 paper appearing in a 2026 transcript gets linked automatically.
what do you know about retrieval-augmented generation?
Claude reads the hot cache, scans index, drills into relevant pages, synthesizes an answer with citations to specific wiki pages. Not training data. Grounded in what you ingested.
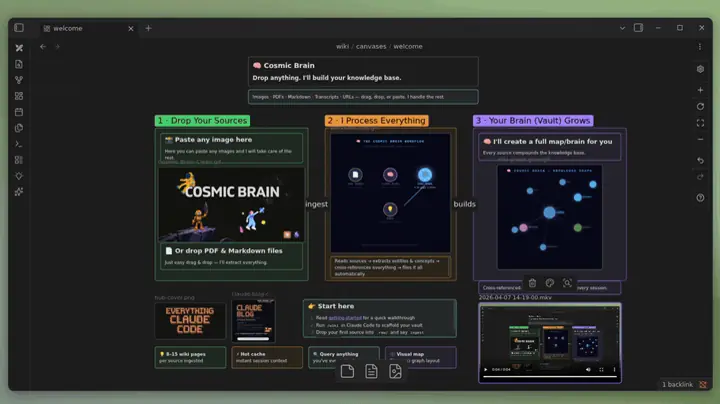
The /canvas, Your Visual Knowledge Layer
The /canvas skill separates claude-obsidian from every other second-brain tool. While competitors give search and Q&A, claude-obsidian gives a visual workspace connected to the wiki.
/canvas add image wiki/meta/workflow-loop.gif /canvas add note Karpathy LLM Wiki /canvas zone Research
Each command adds a node to your Obsidian canvas. Images render inline, wiki pages pin as linked cards, text appears as markdown cards.
The cross-project power move: add this to any Claude Code project CLAUDE.md:
## Wiki Knowledge Base Path: ~/path/to/vault When you need context not in this project: 1. Read wiki/hot.md first 2. If not enough, read wiki/index.md 3. Drill into relevant wiki pages
Your personal knowledge base becomes shared context across every Claude Code project. One source of truth.
RAG vs. The Compounding Wiki
RAG: maintain a document store, run an embedding model, push vectors to a database, run similarity search at query time, inject retrieved chunks into context, get an answer, repeat. Nothing accumulates. Every query starts from the same static corpus.
Compounding wiki: sources are compiled once into structured markdown. The wiki grows. Relationships are explicit links, not similarity scores.
| RAG | claude-obsidian wiki | |
|---|---|---|
| Setup | Vector DB + embedding pipeline | 2 minutes |
| Knowledge accumulation | None, rediscovers each query | Compounds every session |
| Cross-source connections | Similarity-based, implicit | Explicit links, maintained by Claude |
| Maintenance | Manual re-indexing | /lint health check |
| Cost | API + vector DB costs | Free |
| Portability | Vendor lock-in | Local markdown |
| Context efficiency | Chunk retrieval | Structured wiki pages |
Use RAG for: large static document corpora, production search systems, multi-user retrieval, sub-second latency requirements.
Use the wiki for: personal knowledge management, ongoing research across sessions, cross-project context, domains where accuracy and provenance matter more than speed.
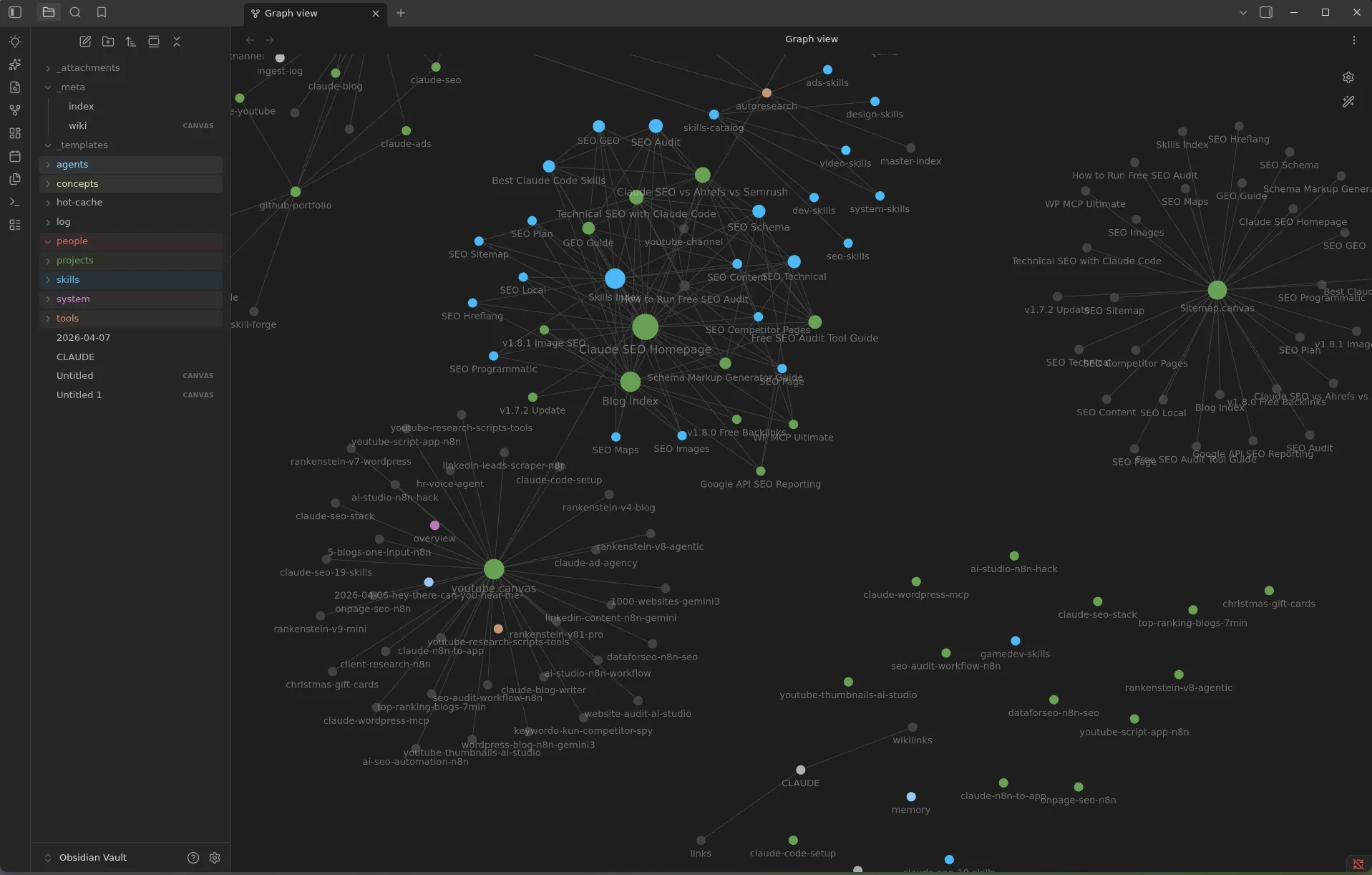
Your Knowledge Graph After 30 Days
After 30 days of regular ingestion, a typical vault has 80 to 200 wiki pages. The Obsidian graph view makes the compounding visible: clusters of related concepts, bridges between domains, orphan nodes signaling gaps.
The /lint command surfaces structural health at any point:
- Orphan pages: wiki entries with no inbound links
- Dead links: references pointing at deleted or renamed pages
- Stale claims: entries that newer content contradicts
- Missing cross-references: connections the system suggests adding
Start Building
Karpathy's insight: use LLMs not just to answer questions, but to build and maintain the knowledge base they answer from. The longer the wiki exists, the better it gets. Knowledge compounds.
claude-obsidian is the practical implementation, free, open source, available in two minutes.
Plugin install (fastest):
claude plugin install github:AgriciDaniel/claude-obsidian
Clone as full vault:
git clone https://github.com/AgriciDaniel/claude-obsidian bash bin/setup-vault.sh
Add to existing vault: copy WIKI.md into your vault root and follow the setup prompt.
Then type /wiki. Drop your first source with ingest. Watch the wiki build itself. Come back tomorrow and it will know everything, plus whatever you added today.
claude-obsidian is open source. Star the repo: github.com/AgriciDaniel/claude-obsidian